
On dit Google toujours plus intelligent, plus efficace dans son exploration d’un site en profondeur et dans la compréhension de ses contenus. On le dit aussi plus fin dans son interprétation des requêtes internautes, apportant ainsi des résultats plus qualitatifs. L’intelligence artificielle a-t-elle évolué au point de ne plus avoir à vous préoccuper de votre référencement et de ses aspects techniques ? Eh bien non, et c’est là toute la subtilité du SEO en 2019. Google est toujours plus exigeant sur ce qu’il attend d’un site internet : exigeant sur le niveau technique d’un site pour réduire son temps d’exploration ; et exigeant sur la qualité des contenus offerts à l’internaute. Voici donc les 2 axes d’optimisations SEO prioritaires en 2019 et que nous conseillons de travailler pour booster vos performances.
La paternité française de l’expression “page zombie” revient à Olivier Duffez qui les décrit comme des pages de mauvaise qualité (seo et contenus), peu ou pas utiles aux internautes, et donc très peu consultées. Lorsqu’elles sont générées en très grand nombre – le webmaster ignorant peut-être leur existence mais pas Google – on parle de “masse noire”.
Ces pages, qui ne sont pas nécessairement indexées, sont explorées par Google, lui faisant perdre du temps en monopolisant le “budget crawl” de GoogleBot. A terme, elles dégradent l’appréciation qualitative que Google fait de votre site, donc ses performances SEO. Par nature, elles offrent souvent aussi une mauvaise expérience utilisateur.
D’ailleurs, les infos de Google sont on ne peut plus explicites :
Gaspiller inutilement des ressources du serveur pour des pages [à faible valeur ajoutée] détournera l’activité d’exploration des pages qui ont réellement de la valeur, ce qui peut considérablement retarder la découverte de contenus intéressants sur un site.
Mais qu’est-ce qu’une page “à faible valeur ajoutée”, ou “page zombie” ?
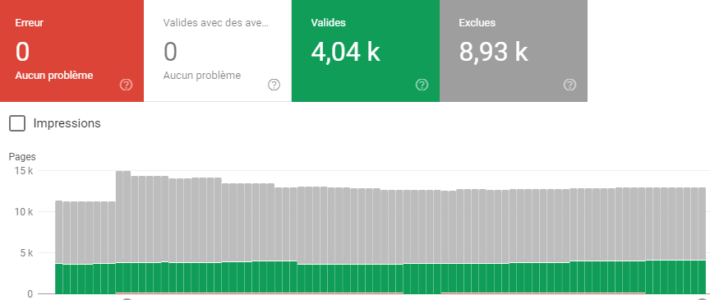
Bonne nouvelle, elles sont majoritairement accessibles dans la Google Search Console (rapport de Couverture). Ci-dessous, près de 9000 url sont explorées mais non indexées ; 4000 sont indexées, dont une majeure partie entrant aussi dans la catégorie des pages inutiles :
On entend par budget crawl, le temps qu’accorde GoogleBot à l’exploration d’un site. Ce temps d’exploration est variable selon la nature du site, sa popularité, la fréquence de mise à jour de ses contenus, le temps de réponse serveur… Bref, GoogleBot n’explore jamais toutes les url d’un site à chaque passage. La notion était connue depuis plusieurs années, mais Google n’a officiellement communiqué dessus qu’en 2017.
Le budget crawl n’est donc pas illimité, d’autant plus qu’explorer un site web, dont sa masse noire, et indexer ses milliers d’url, exploite de gigantesques ressources serveurs qui coûtent cher à Google (facture énergétique). Et ces ressources serveurs surexploitées ont un énorme coût environnemental pour la planète (l’énergie employée à refroidir les data centers de Google n’est qu’à 30% issue de sources renouvelables). Si l’on ne connaît pas précisément la consommation électrique de Google, on peut la comparer aux transactions en Bitcoin dont la consommation d’électricité a dépassé celle du Nigéria et du Danemark !
Vous l’aurez compris, le traitement des pages inutiles est une question d’économie de ressources et d’hygiène technique.
Si vous limitez le nombre d’url explorables et indexables, Google se concentrera sur vos meilleures pages et prendra en compte plus rapidement vos nouveaux contenus et vos optimisations.
Inversement, si votre site présente plusieurs milliers d’url explorables et indexables, dont une trop grande partie sans intérêt pour l’internaute et Google (url avec variables, contenus dupliqués, contenus pauvres, pages d’erreurs…), le temps utile à l’exploration des pages à valeur ajoutée sera plus faible. La qualité globale des performances du référencement s’en ressentira à moyen terme.
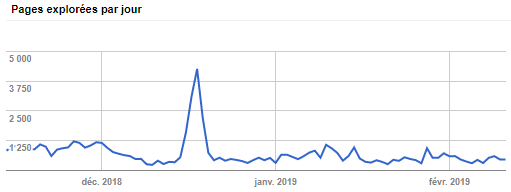
Dans l’exemple ci-dessous, les statistiques d’exploration d’un site dans la Google Search Console indiquent une moyenne de 700 pages explorées par jour pour plus de 4000 pages indexées selon la même Google Search Console : il y a motif à optimisation du budget crawl.
La chasse aux pages zombies et au gaspillage des ressources d’exploration passe donc par une rationalisation des urls proposées à GoogleBot en éliminant les pages de faible valeur :
Nota bene : la balise noindex bloque l’indexation (= le référencement d’une url dans les résultats de recherche), mais non le crawl (= l’exploration par le robot). Les pages inutiles traitées avec la balise noindex continueront de monopoliser du budget crawl.
Il y a encore peu de temps, une page ne pouvait pas se positionner dans le top 10 Google (ou très rarement), si elle ne contenait pas le terme de recherche dans sa balise Title. L’intelligence de Google est de ne plus se contenter d’évaluer la présence d’un terme de recherche dans un contenu, mais de comprendre la requête et de prédire le contenu qui sera le plus en adéquation avec l’intérêt de recherche d’un internaute.
C’est tout l’enjeu de RankBrain, une composante de l’algorithme de Google utilisant des méthodes d’apprentissage automatique (machine learning), et destinée à mieux répondre aux questions des internautes, écrites et vocales.
Début février 2019, Gary Illyes de Google expliquait ainsi RankBrain sur le forum Reddit :
RankBrain est une composante du ranking sur base d’apprentissage automatique PR-sexy [PR pour PageRank] qui utilise les données de recherche historiques pour prédire sur quoi cliquerait le plus probablement un utilisateur sur une requête n’ayant jamais été tapée auparavant.
Attention cependant à ne pas trop fantasmer sur l’intelligence artificielle de Google ! D’une part, RankBrain n’est pas totalement déployé. D’autre part, RankBrain s’applique à l’interprétation des recherches, non des contenus. Et enfin, de l’aveu même des ingénieurs travaillant sur le sujet, Google comprend le fonctionnement de RankBrain, mais pas vraiment ce qu’il fait !
*SERP = Search Engine Result Pages, pages de résultats des moteurs de recherche
Certains résultats sont parlants : les titres ne contiennent absolument aucun des termes de recherche. Google joue à Jeopardy !
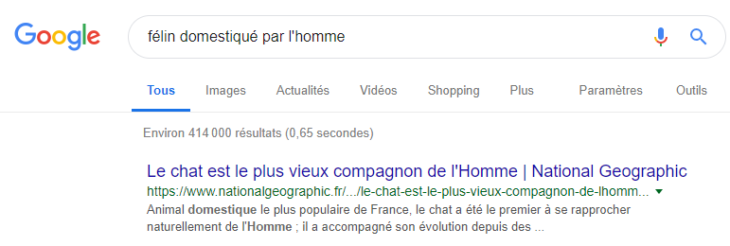
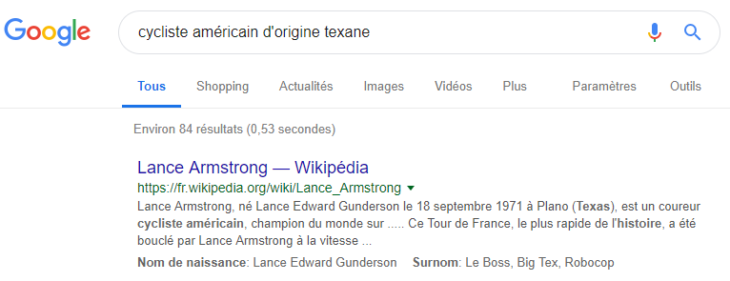
Et, depuis 2016, on voit fleurir des réponses au-dessus des résultats de recherche (la fameuse position zéro) sous forme de bloc texte + image ou de tableau comme ci-dessous. Nous sommes bien passé d’un moteur de recherche à un “moteur de réponse” comme Olivier Andrieu l’a appelé il y a déjà plusieurs années. Notez aussi que Google reformule les questions posées en relation sous la position zéro.
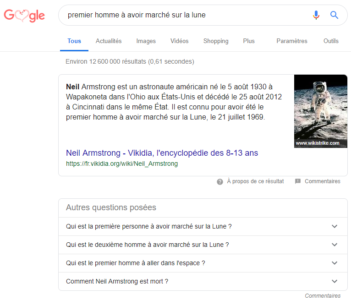
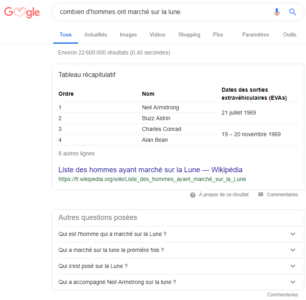
A la vue de ces évolutions qui vont sans aucun doute continuer à se développer dans les mois à venir, vous approprier les intentions de recherche de vos internautes cibles nous paraît essentiel pour une stratégie SEO orientée contenus. Et – ce qui pouvait paraître paradoxal auparavant – il s’agit de passer d’une logique de contenus seo-friendly (= travailler sur des mots-clés à fort volume de trafic) à une logique de marketing de l’intention (= travailler sur les besoins en informations de chacune de ses cibles de communication en amont de l’acte d’achat).
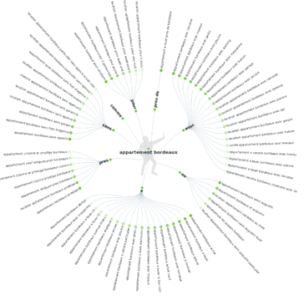 L’étape n°1 est d’identifier et structurer les intentions de recherche de vos cibles :
L’étape n°1 est d’identifier et structurer les intentions de recherche de vos cibles :
Vous pouvez aussi recouper ces données avec les volumes de recherche présentés dans l’Outil de Planification de Mots-clés de Google Ads (ex Google AdWords).
Ces informations en votre possession, vous les organiserez en thématiques et sous-thématiques dans un fichier Excel ou un outil de mind mapping. Si ce travail est bien fait, vous aurez une continuité sémantique entre le général et le particulier, base de la conception d’un cocon sémantique.
Avantage non négligeable, en raisonnant “contenus répondant à une intention de recherche”, vous offrez des contenus plus précis, plus riches, donc aptes à capter du trafic naturel plus qualifié, mais aussi des backlinks spontanés bons pour votre PageRank.
Enfin, plus besoin de se creuser la tête pour trouver des sujets de contenus, votre feuille de route est toute tracée pour les mois à venir !
Nous sommes fiers que notre travail UX / UI / web
ait été remarqué avec plusieurs récompenses prestigieuses.


